*Denotes co-first authorship. †Denotes co-last authors.
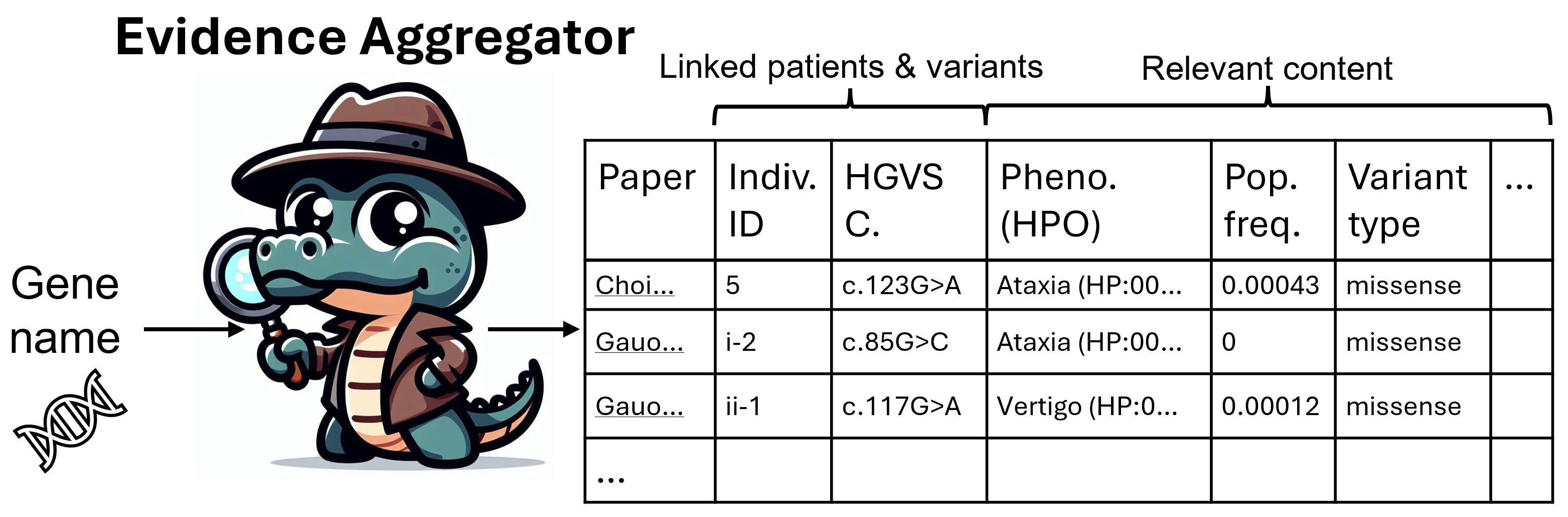
Evidence Aggregator: AI reasoning applied to rare disease diagnostics
We developed the Evidence Aggregator (EvAgg), a generative AI tool designed for rare disease diagnosis that systematically extracts relevant information from the scientific literature for any human gene. EvAgg reduced analyst review time by 34% (p<0.002) and increased papers, variants, and cases evaluated per unit time, with 97% recall identifying relevant papers.

Tackling the complexity of cancer with generative models
A perspective and framework for leveraging generative AI models to address the complexity and heterogeneity of cancer, enabling more precise therapeutic strategies.

Predicting evolutionary rate as a pretraining task improves genome language model representations

A biologically annotated neural network for proteomic discovery in Parkinson's disease
A biologically annotated neural network framework leveraging proteomics data to identify novel biomarkers and mechanisms in Parkinson's disease.
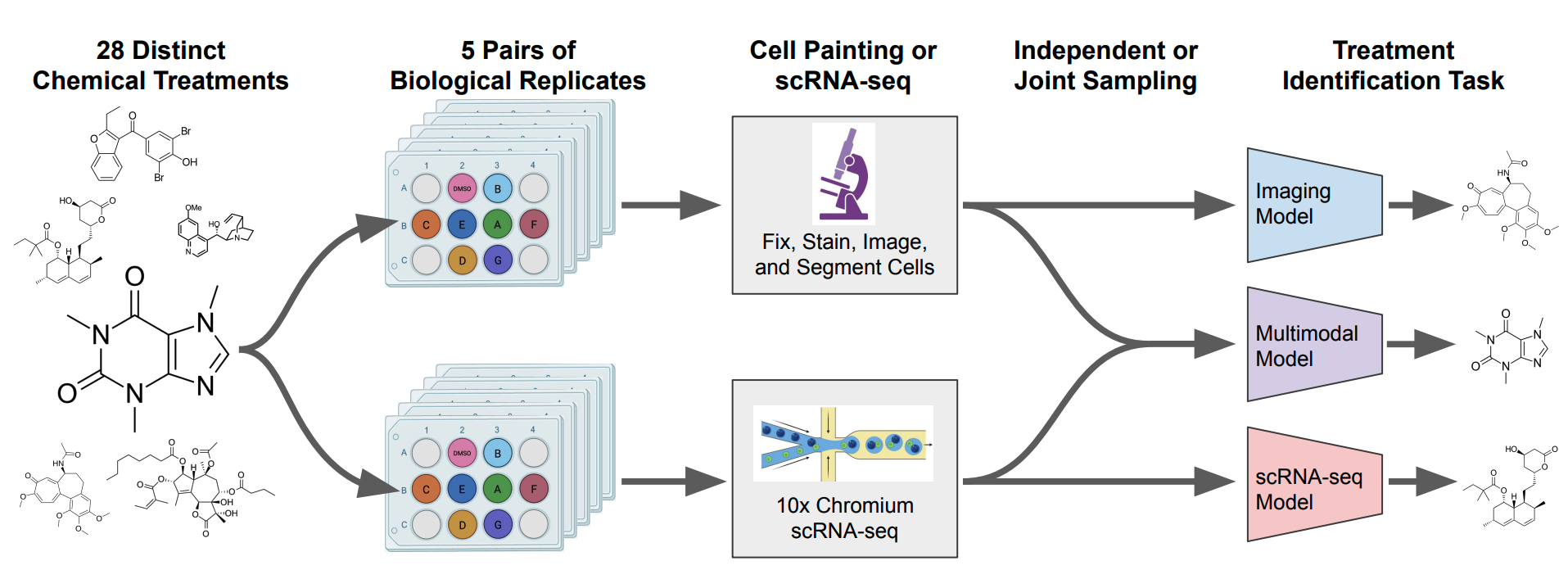
scGeneScope: A Treatment-Matched Single Cell Imaging and Transcriptomics Dataset and Benchmark for Treatment Response Modeling
scGeneScope as the first large-scale, high-quality treatment-matched multiprofile dataset for single-cell biology with over 627k scRNA-seq profiles and 716k Cell Painting images from identical chemical treatments across 28 diverse mechanisms of action. In our paper, we present this dataset and challenge the hype around foundation models by providing a realistic testbed to enable rigorous benchmarking of ML models (linear to foundation models) for drug discovery.
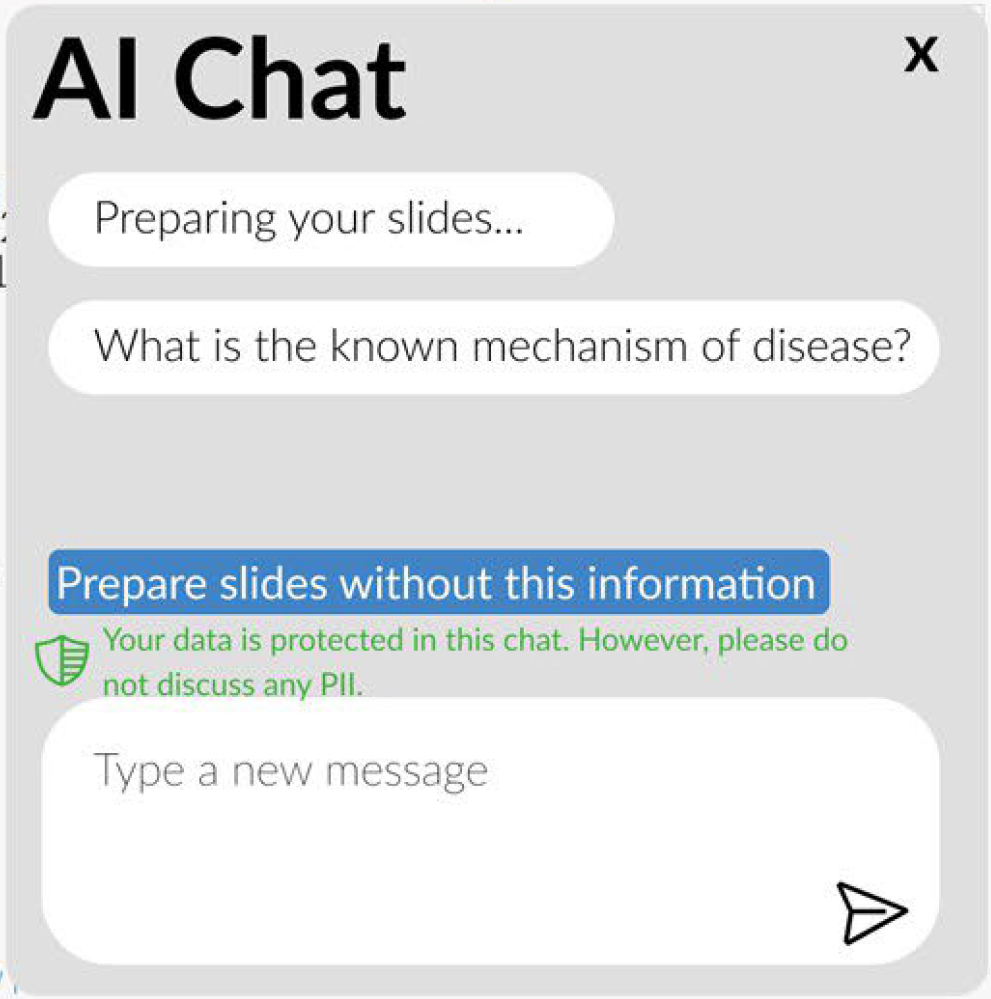
AI-Enhanced Sensemaking: Exploring the Design of a Generative AI-Based Assistant to Support Genetic Professionals
We co-designed a generative AI assistant with genetics professionals to support genome sequencing analysis for rare disease diagnosis. By identifying key challenges in sensemaking and reanalysis, we developed and prototyped AI features that help synthesize variant evidence and flag cases for reanalysis, ultimately aiming to increase diagnostic yield and reduce time to diagnosis.
Evidence Aggregator: AI reasoning applied to rare disease diagnostics
We developed a large language model (LLM)-powered framework, EvAgg, to aggregate and synthesize rare disease literature and related content, enabling clinical genomic analysts to review patient cases more rapidly and thoroughly in research settings. EvAgg reduced case review time by 34% (p < 0.002) and significantly increased the throughput of papers, variants, and cases analyzed.
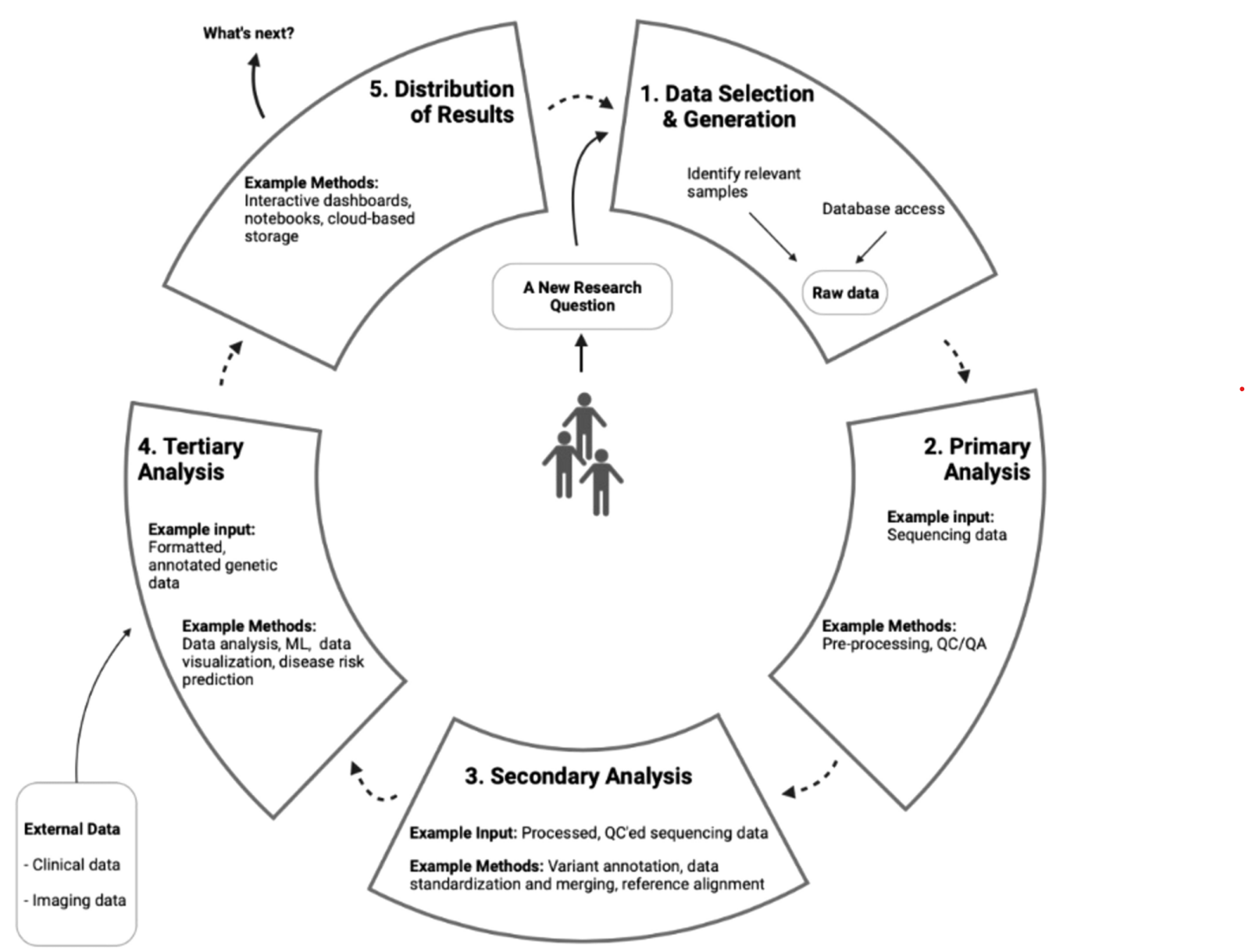
Addressing biomedical data challenges and opportunities to inform a large-scale data lifecycle for enhanced data sharing, interoperability, analysis, and collaboration across stakeholders
We conducted a qualitative study to identify common challenges and data tasks across the biomedical discovery lifecycle by interviewing professionals from diverse roles in the field. Based on these insights, we proposed seven actionable recommendations to improve data quality, interoperability, and collaboration for precision medicine research.
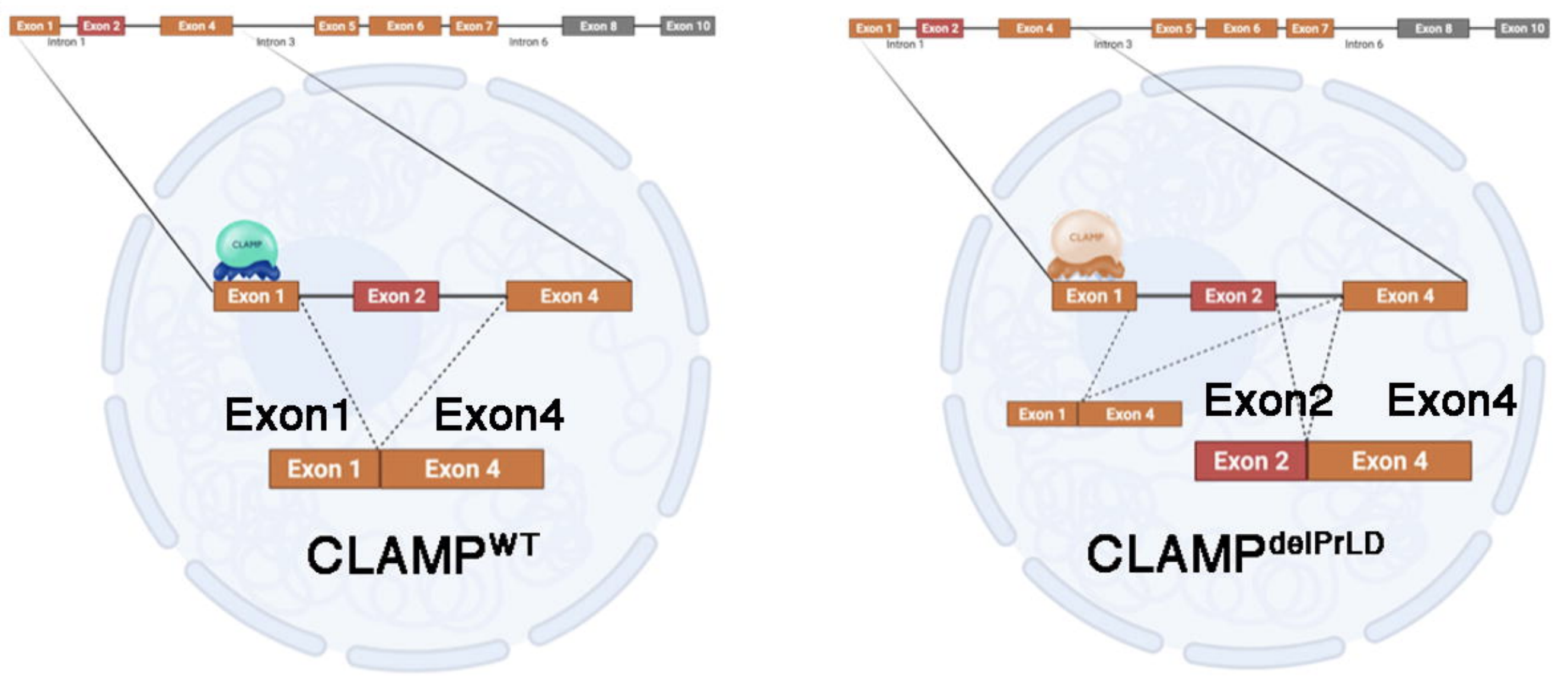
Dual DNA/RNA-binding factor regulates dynamics of hnRNP splicing condensates
Here we show that the transcription factor CLAMP doesn't just bind DNA, it also directly binds RNA and spliceosomal proteins through its prion-like domain, linking transcription to sex-specific alternative splicing. By regulating the dynamics of hnRNP splicing condensates, CLAMP ensures precise, sex-dependent splicing outcomes, revealing a new mechanism where transcription factors act as master organizers of splicing decisions.
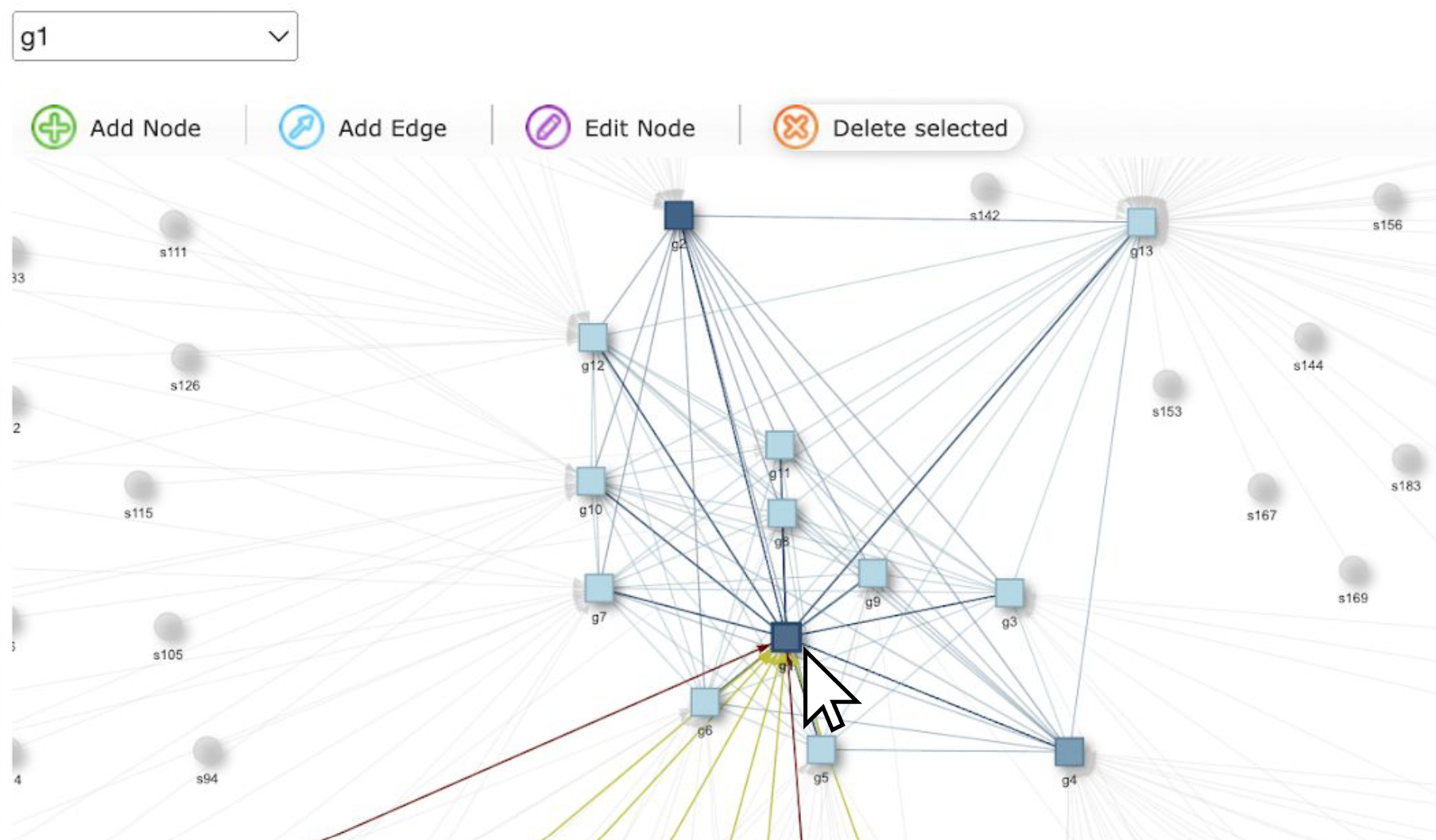
Multioviz: an interactive platform for in silico perturbation and interrogation of gene regulatory networks
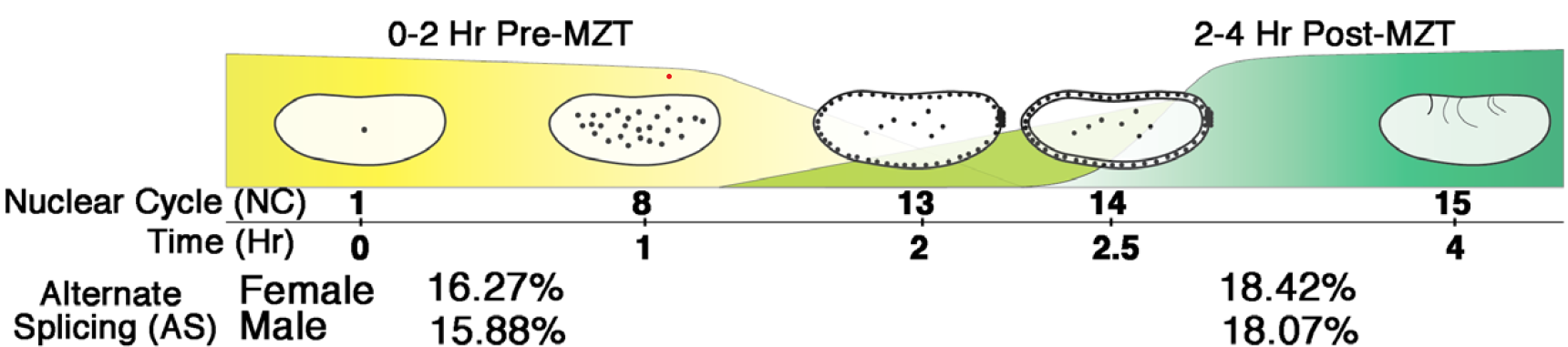
Sex-specific splicing occurs genome-wide during early Drosophila embryogenesis
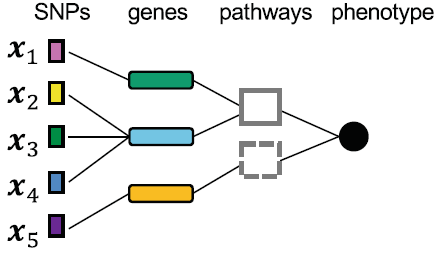
A spectrum of explainable and interpretable machine learning approaches for genomic studies
We discuss the spectrum of machine learning model transparency, from black box to explainable to interpretable, highlighting methods tailored for genomic studies. Our focus was on how incorporating biological knowledge into model design can improve both predictive performance and scientific insight for precision medicine.
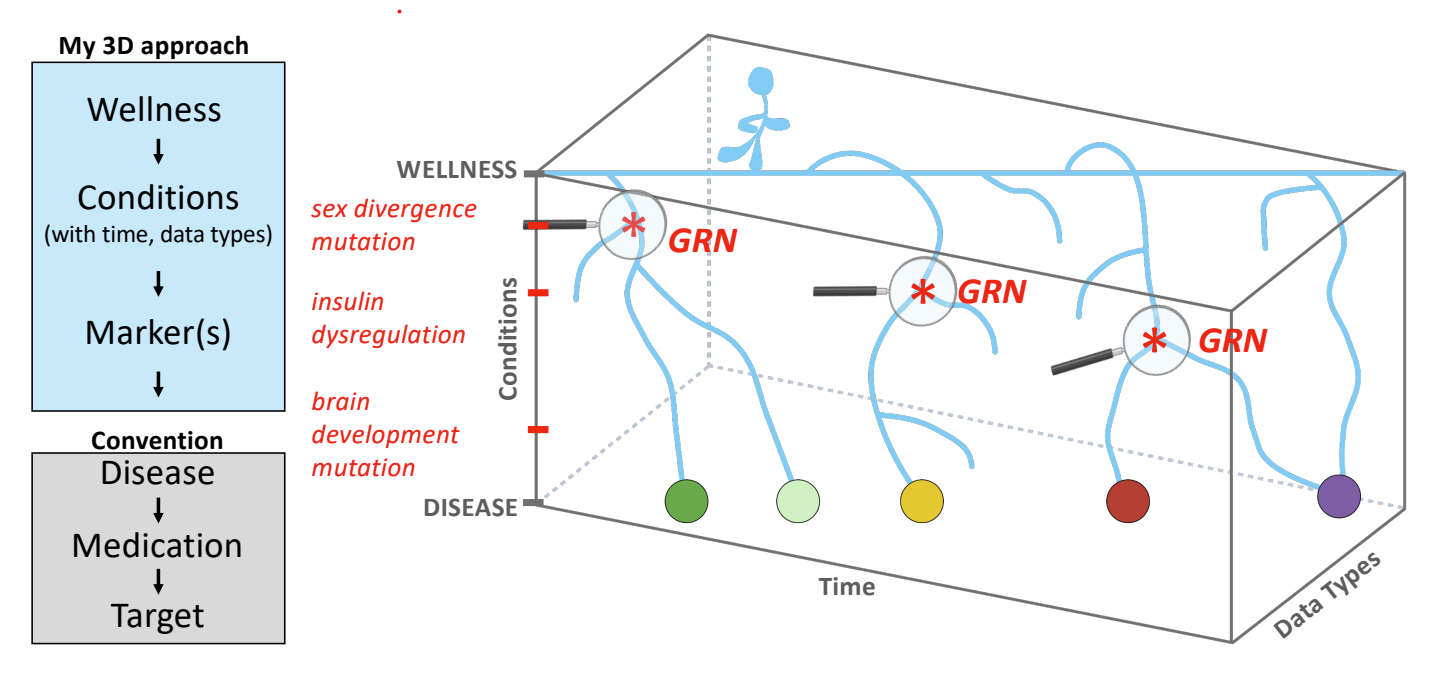
It's About Time: Interpretable Methods and Associated Interactive Platforms to Uncover Regulatory Mechanisms from Temporal and Multi-Omics Data
We developed three interactive computational tools to uncover gene regulatory networks from temporal multi-omics data, focusing on transcription factor dynamics and sex-specific regulation. These platforms empower researchers to generate hypotheses, validate findings, and accelerate discovery, bringing us closer to personalized therapeutics.
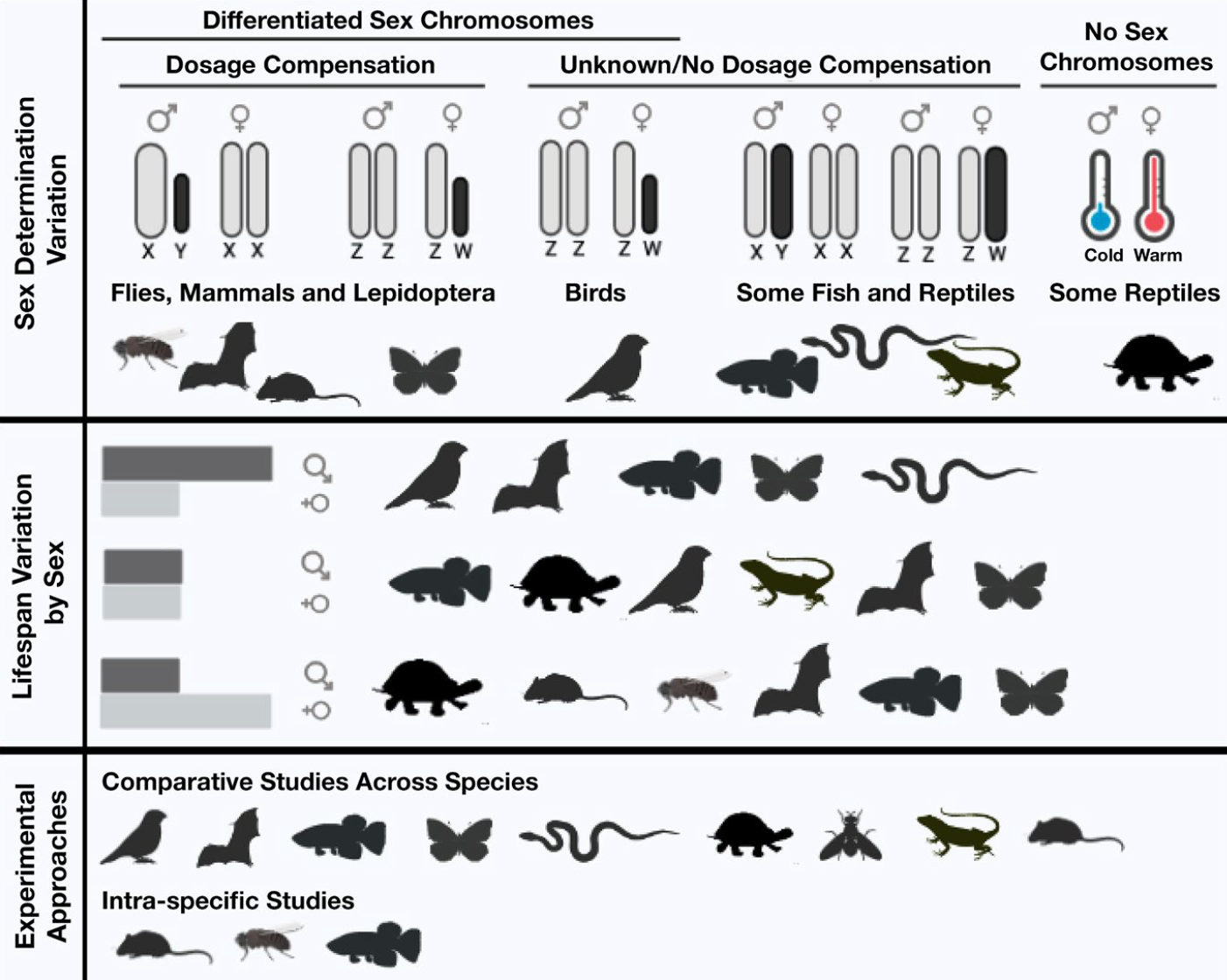
Sex-specific aging in animals: Perspective and future directions
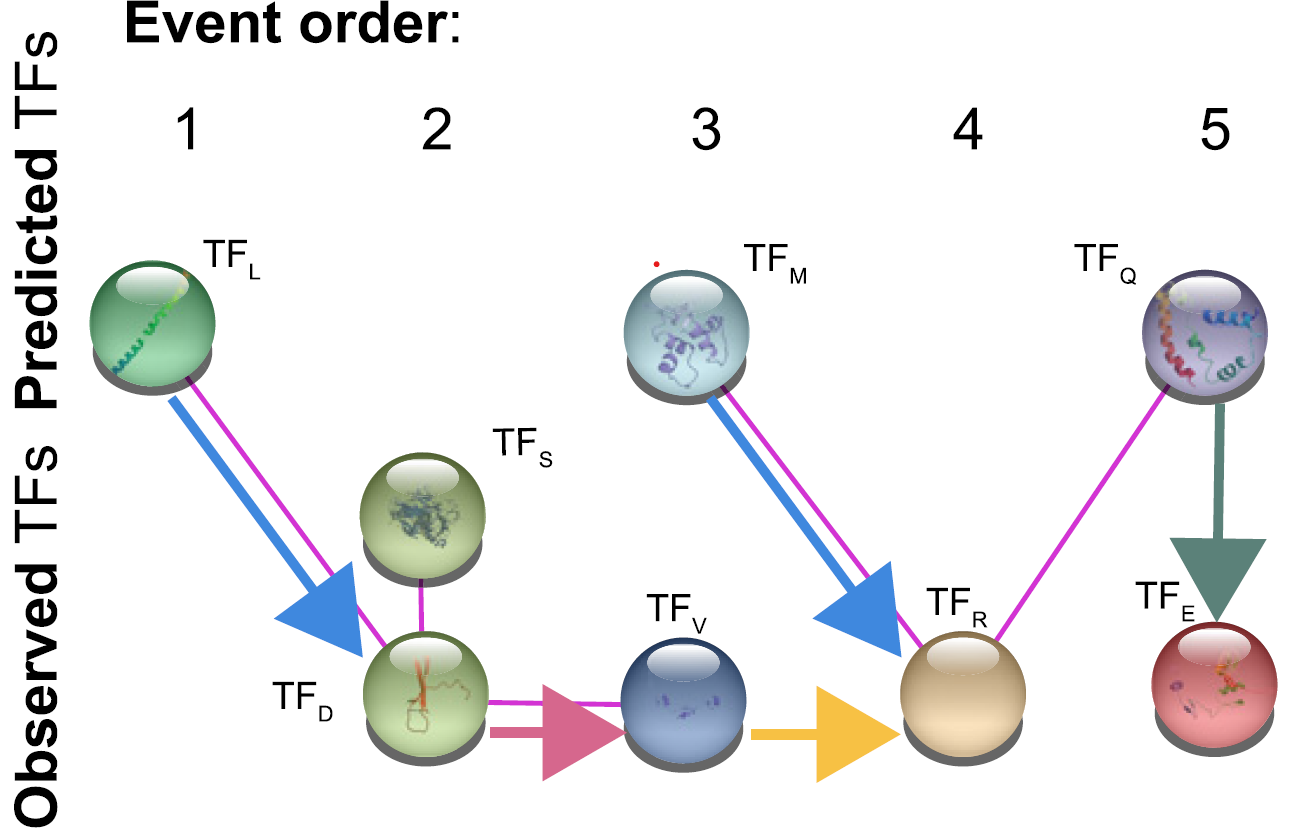
TIMEOR: a web-based tool to uncover temporal regulatory mechanisms from multi-omics data
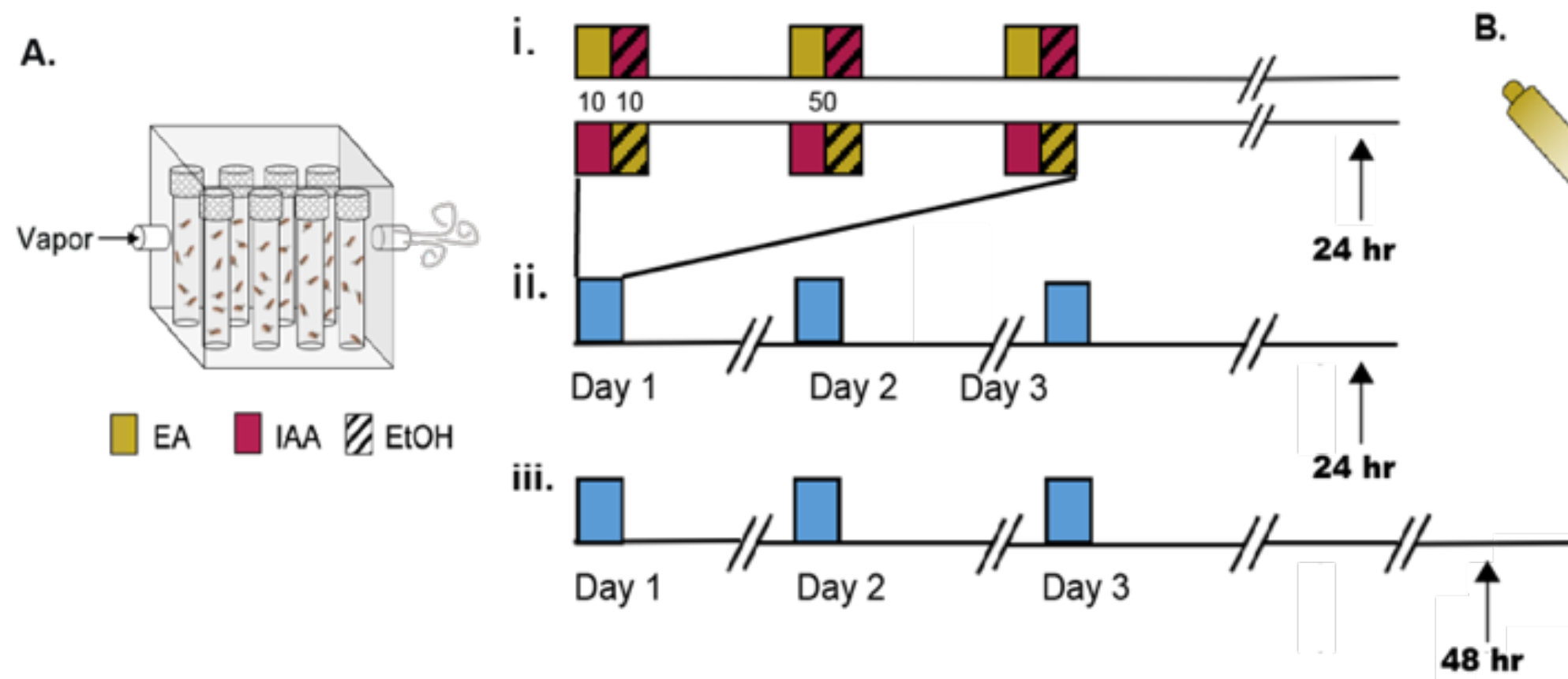
Neuromolecular and behavioral effects of ethanol deprivation in Drosophila
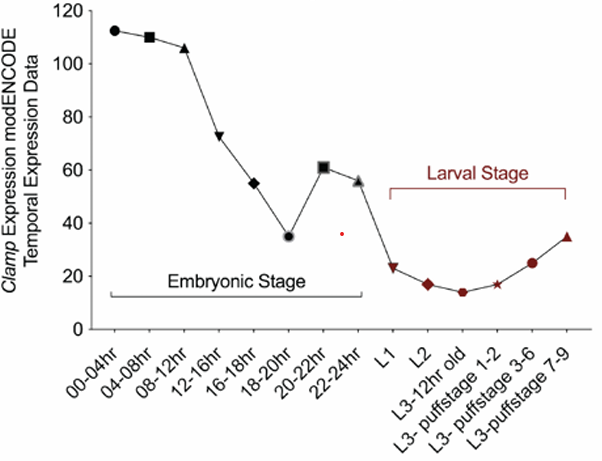
The transcription factor CLAMP is required for neurogenesis in Drosophila melanogaster
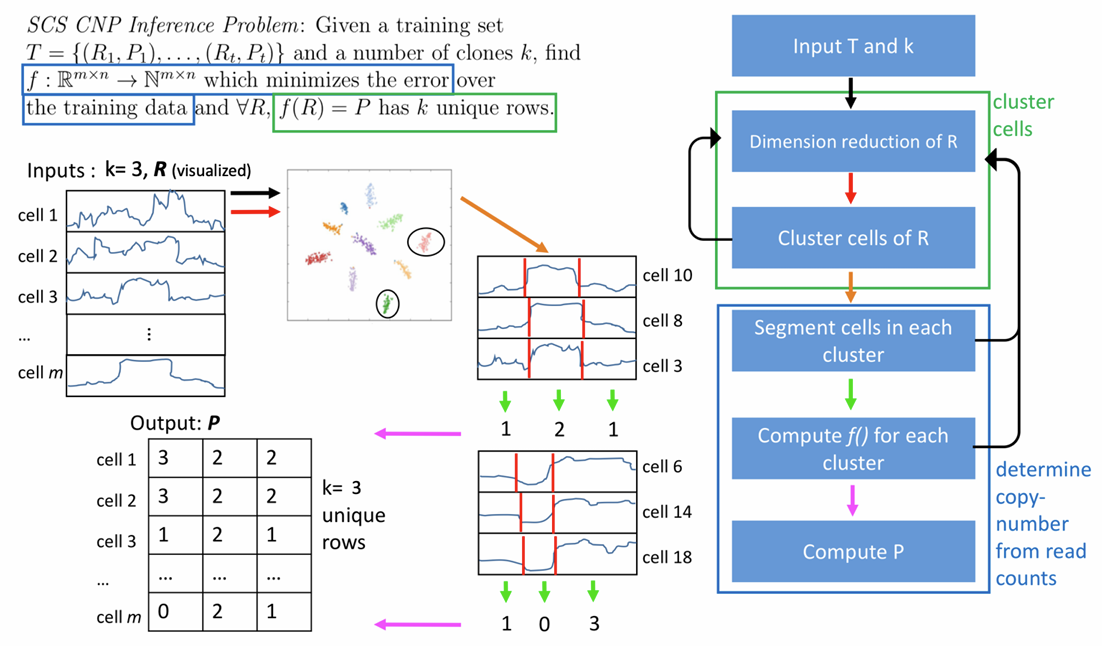
Identification of Subclonal Drivers and Copy-Number Variants from Bulk and Single-Cell DNA Sequencing of Tumors

Highlights from the ISCB Student Council Symposia in 2016
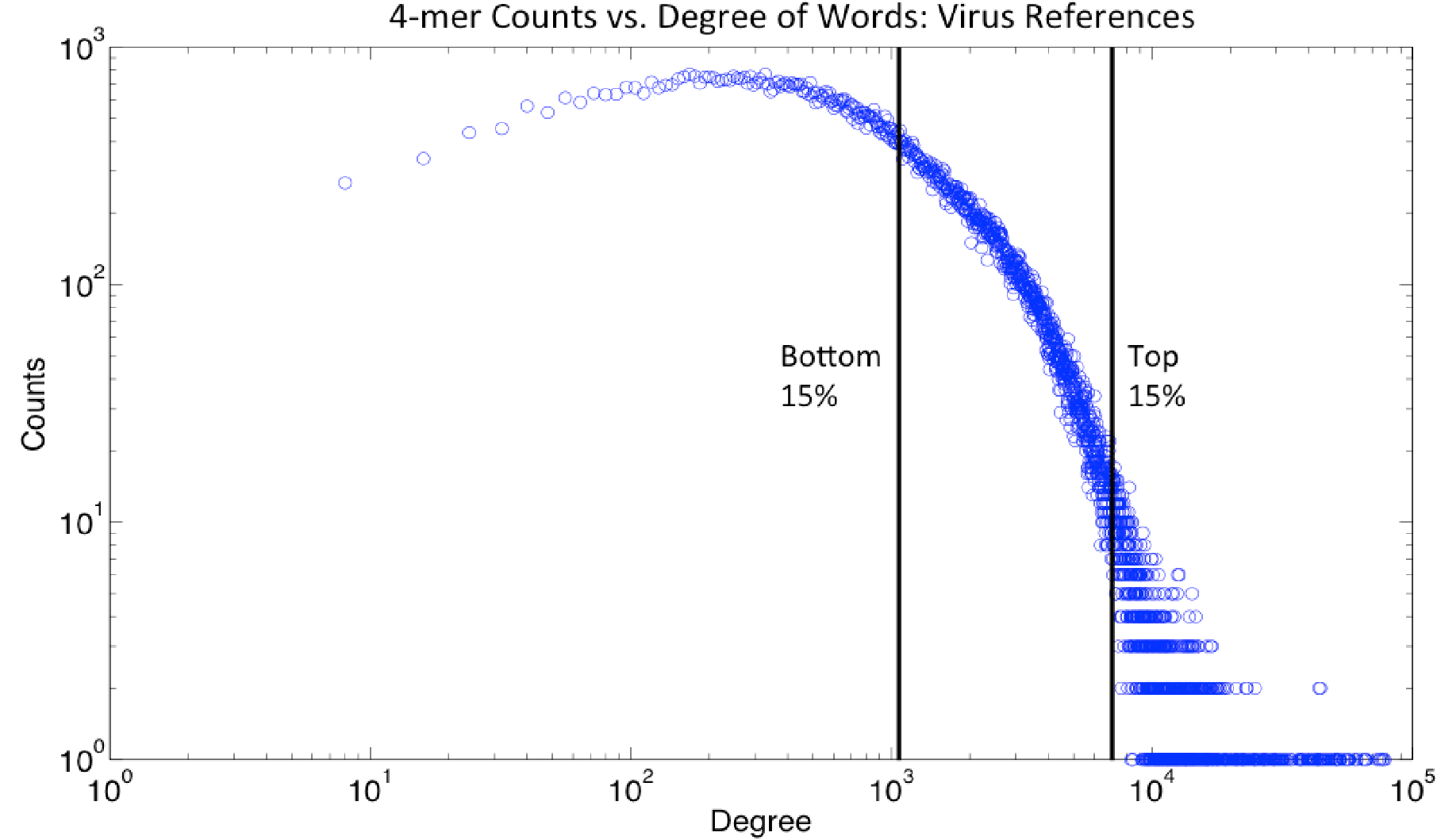
Using a Big Data Database to Identify Pathogens in Protein Data Space
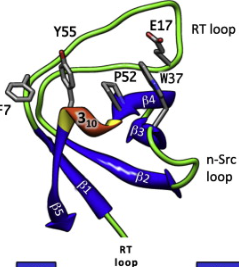
Determining the winning SH3 coalition: how cooperative game theory reveals the importance of domain residues in peptide binding
scGeneScope
scGeneScope code enables benchmarking for treatment response modeling of our generated perturbationally-paired single cell RNA-seq and Cell Painting image dataset.
The Evidence Aggregator
The Evidence Aggregator is a large language model (LLM)-powered framework that aggregates and synthesizes rare disease literature and related content.
time2splice
time2splice is a method to find temporal and sex-specific alternative splicing from multi-omics data.
TIMEOR
TIMEOR is a web server and Dockerized command line tool to identify gene regulatory networks and assign mechanism from temporal and multi-omics data.
PRIPS
A fast protein analysis algorithm using D4M, merging triplestore/NoSQL databases with associative array representations of proteomic sequences for fast big data analysis.
Property of MIT Lincoln Laboratory
Chemical Inventory Database
Web-based inventory management system used in academic departments. Users log in and scan barcodes for automatic item entry.
Property of DePauw
Arduino-CSSI
Set of Arduino workshop modules and Fritzing diagrams to teach students how to program as part of the Google Computer Science Summer Institute.
Property of Google
Instrument Control
Online internal system to monitor product batch data extracted from Eli Lilly's Data Mart and Data Warehouse databases.
Property of Eli Lilly and Elanco